Knowledge Graph Papers @ ICLR 2021
25 Mar 2022 | graphs knowledge-graph representation-learningHi! 👋 Today we are going to have a look at ICLR 2021 papers focusing on knowledge graphs (KGs), particularly in areas of graph representation learning and NLP. Among 860 accepted papers we highlight 10 particularly interesting and promising works that might influence the field in near future. This post is be structured as follows:
- Reasoning in KGs
- Temporal Logics and KGs
- NLP Perspective: Relations, PMI, Entity Linking
- Complex Question Answering: More Modalities
- Conclusion
Reasoning in KGs
Query embedding and neural query answering are quite hot topics today, and such systems are way more capable in complex reasoning than N+1’th KG embedding model.
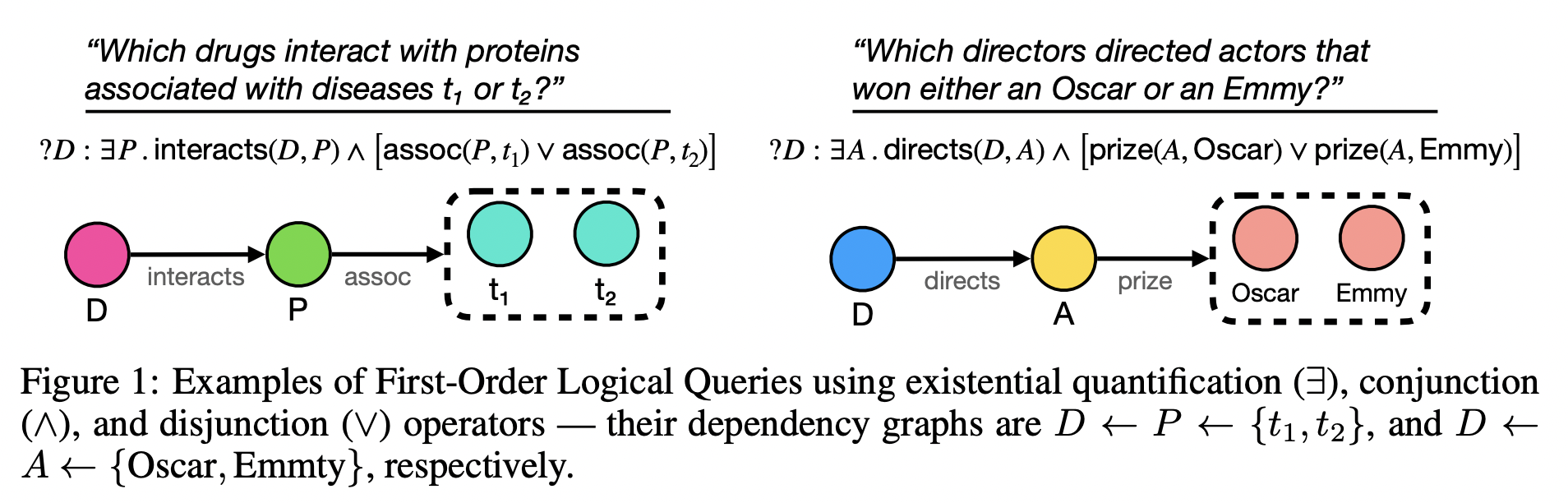
Usually, in query embedding, you have to embed a lot of possible combinations of atoms which could easily be 50M points induced by 1-hop, 2-hop, AND, OR, etc queries. That is, starting from a relatively small graph (a subset of Freebase of 270K edges is a typical benchmark) you have to embed orders of magnitude more points. Is it really necessary? 🤨
Surprisingly, no! Arakelyan, Daza, Minervini, and Cochez show that it is pretty much enough to take any pre-trained KG embedding model (trained only on 1-hop queries in the form head, relation, ? ) and decode them in a smart way. The authors propose CQD (Continuous Query Decomposition) with two options: 1) model queries with t-norms (continuous optimization); 2) just use a beam search (combinatorial optimization) similar to that of your favourite NLG transformer. That is, you simply traverse the embedding space with beam search and you don’t need all those redundant millions of points. 👨🔬 In the experiments, the beam search strategy performs very well and leaves far behind the previous approaches that do model those millions explicitly. That’s a neat result and, in my opinion, will be a very strong baseline for all future works in this domain. Well deserved Outstanding ICLR’21 Paper award! 🙌
 Source: Arakelyan, Daza, Minervini, and Cochez
Source: Arakelyan, Daza, Minervini, and Cochez
Continuing with rules and reasoning, Qu, Chen et al take another direction and propose RNNLogic which algorithm is depicted below 👇. RNNLogic employs relational paths that can be mined from the background KG and, hence, generated after some learning procedure. Given a query head, relation, ? , we first generate a set of rules (sequence of relations parameterized by LSTM, RNN-part of the name comes from here) from which we sample ‘most plausible’ rules and then send them into the predictor to produce scores over possible answers. That is, the generator tries to predict better and better rules pruning the search space for the predictor. The predictor can be parameterized by entity and relation embeddings akin to RotatE, which shows observable improvements in the experiments. During inference, RNNLogic not only predicts a target entity of a query, but also supports it with a bunch of relevant rules which positively impacts explainability, a common pitfall of embeddings-only algorithms.
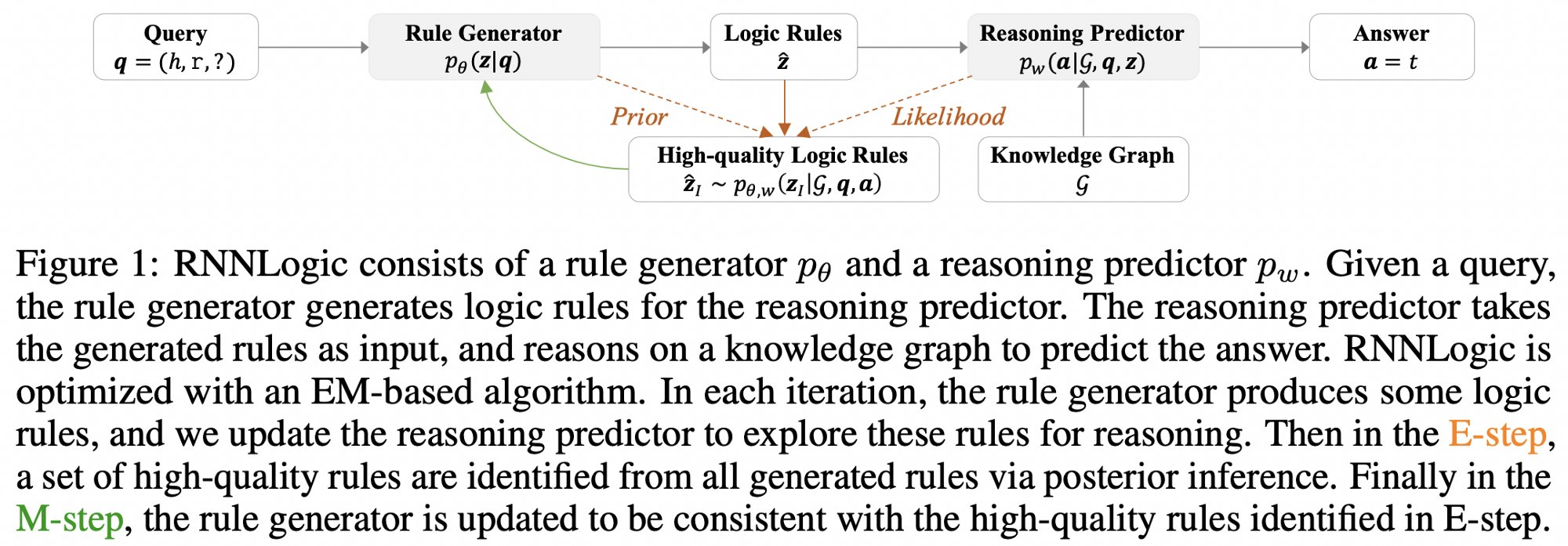 RNNLogic. Source: Qu, Chen et al
RNNLogic. Source: Qu, Chen et al
Temporal Logics and KGs
Inthe temporal setup, we add a time dimension to our KG. That is, now we have timestamped quadruples (head, relation, tail, time) as data points and hence our queries are (head, relation, ?, time). In other words, a model has to take into account when a particular relation happened.
At ICLR’21, Han, Chen, et al propose xERTE, an attention-based model capable of predicting future links 🧙♂️. The crux of xERTE is iterative subgraph expansion around head and this expansion keeps track of seen timestamps so that prior links do not have access to the posterior ones. In some sense, it can be seen as a temporal extension of GraIL (ICML’20). Each node embedding is obtained through a concatenation of entity embedding and time embedding (which happens to be a d-dimensional vector of cosines of varying frequencies). Then, in L steps, usually less than 4, xERTE computes attention over the neighbours, prunes the subgraph to retain only the most probable nodes, and yields a distribution of attention scores over candidates (🖼 👇). Thanks to the iterative nature, xERTE can visualize reasoning paths of ranked predictions which was well appreciated by 50+ participants of the user study!
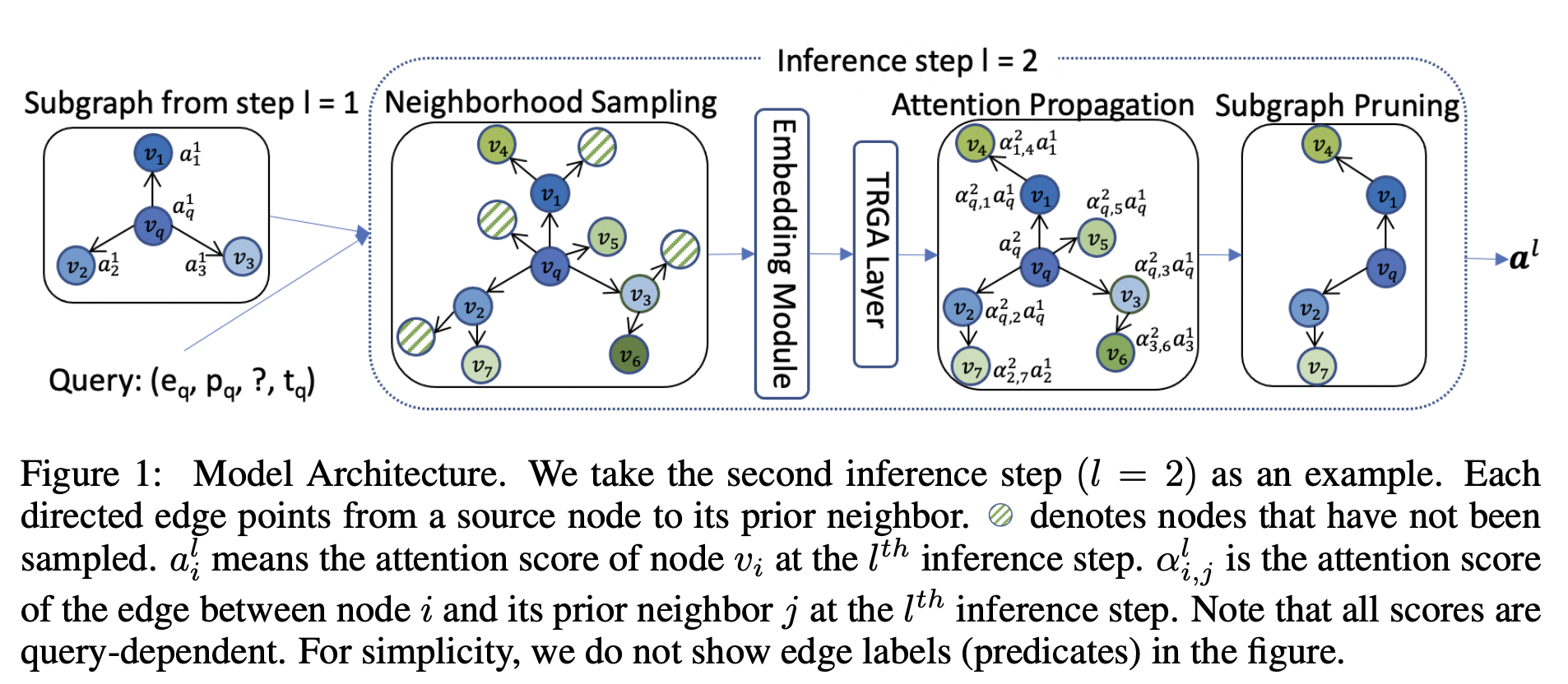 xERTE. Source: Han, Chen, et al
xERTE. Source: Han, Chen, et al
I’d also put in this section a very interesting work by Hahn et al on learning to solve Linear Temporal Logic (LTL) formulas which are widely used in formal verification. LTL is based on propositional logic with temporal operators Next (some formula holds in the next position of a sequence), Until (some formula f holds until g holds), “every point in time”, and “future point in time”. The formulas might look like this, i.e., they are pretty long sequences of atoms and operators:
 LTL examples. Source: Hahn et al
LTL examples. Source: Hahn et al
The authors pose the task of predicting a solution of LTL formulas by generating a satisfiable trace 👣. What do we do with sequences? Put them into the Transformer, of course.
Enhanced with tree-based positional encodings of such long formulas, the authors find that even a relatively small Transformer (8 layers, 8 heads, 1024 FC size) yields surprisingly good results, accurate both semantically and syntactically. Since verifying logical formulas is much simpler than finding them (usually log vs polynomial), the Transformer could generate plausible solutions which then can be verified by non-neural solvers. Furthermore, the authors observe that the Transformer can generalize to the semantics of LTL and perform well on larger/longer formulas compared to training formulas!
NLP Perspective: Relations, PMI, Entity Linking
There is a good amount of NLP-related research involving KGs this year.
First, Allen, Balažević, and Hospedales study the nature of learnable relation embedding in KGs from the PMI (pointwise mutual information) point of view. Back in 2014, Levy and Goldberg showed (in their very influential paper) that learning word2vec implicitly factorizes a PMI matrix of words co-occurrences. Then it was shown that we could extract particular semantic concepts like relatedness, paraphrase, similarity, and analogy from that PMI matrix. Can we draw some parallels and observe such patterns in learnable KG relations?
Turns out yes! The authors identified 3 possible categories of relations: 1) those which signal about the relatedness of two nodes (eg, verb_group relation in Wordnet); 2) those which exhibit specialization (hyponym-hypernym); 3) most common context shift (eg, meronym). Furthermore, the matrices of relatedness-type relations tend to be more symmetric, and eigenvalues/norms of relation matrices/vectors indicate the strength of relatedness. The authors then demonstrate that multiplicative models like DistMult or TuckER better capture such relatedness relation types in KGs. 🏃♀ Chasing SOTA, current KG embedding literature lacks deep analysis of what is actually learned there, and it’s great to see such a long-needed qualitative study!
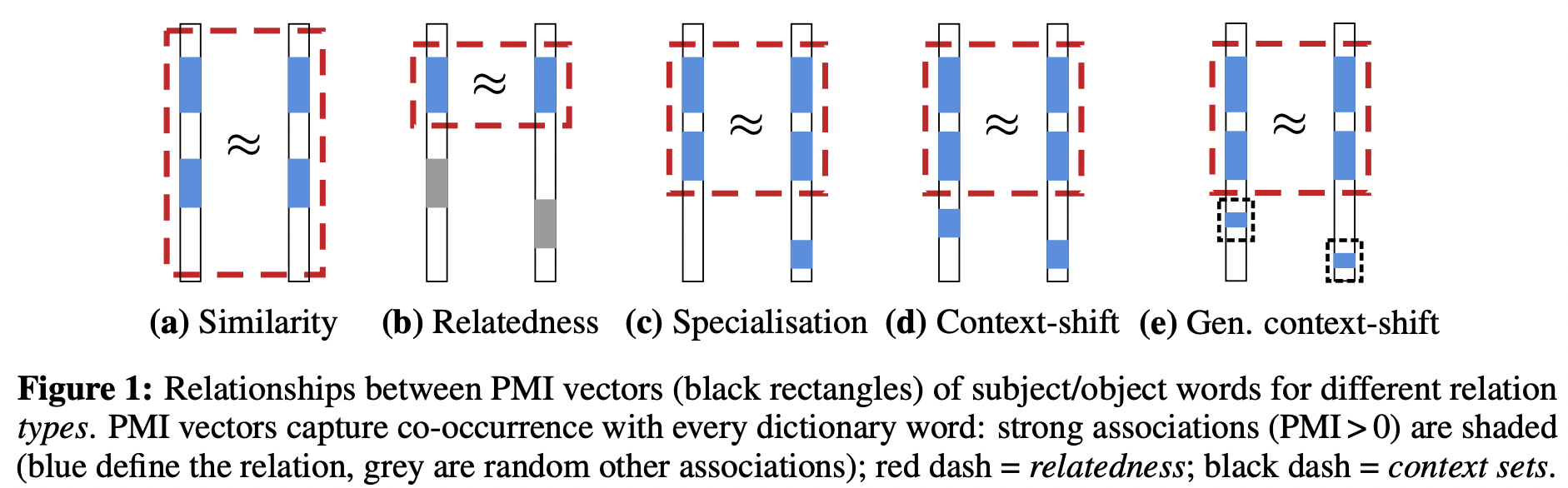 Source: Allen, Balažević, and Hospedales
Source: Allen, Balažević, and Hospedales
Ding, Wang, et al also present a work focusing on relations, but this time in a context of relation extraction from raw texts and learning relation prototypes. That is, instead of learning to distinguish hundreds of unique relations (where some of them might be semantically similar), we’d rather learn a smaller set of centroids/prototypes which would group similar relations together on a manifold — the authors propose a unit sphere (see illustration). For pre-training, the authors use weak labels from Wikidata using their relations together with mapped entities from Wikipedia. The resulting approach performs particularly well in zero- and few-shot scenario with up to 10% of absolute improvement 💪.
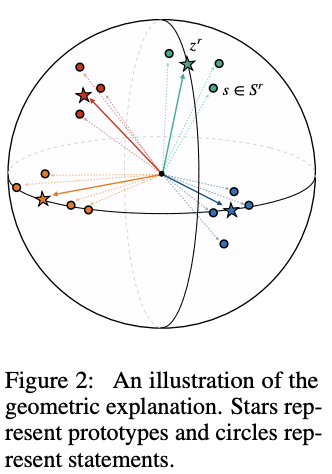 Relation prototypes. Source: Ding, Wang, et al
Relation prototypes. Source: Ding, Wang, et al
Moving towards entities, De Cao et al propose another look onto the entity linking task. Usually, in retrievers and entity linkers such as DPR or BLINK, you have to keep in memory the whole index of named entities where lots of entities have certain tokens in common, eg., “Leonardo DiCaprio”, “Leonardo da Vinci”, “New York”, “New Jersey”, etc.
Of course, in large knowledge bases of millions of entities this leads to a large memory consumption and a necessity to have hard negative samples during training to be able to distinguish between “New York” and “New Jersey”. Instead, the authors propose GENRE (generative entity retrieval) to generate entity names autoregressively (token by token) given a context (check out an awesome illustration below 👇). As a backbone, the authors use BART to fine-tune on generating entity names. The inference process using a beam search is a bit more cumbersome: since we want to prune impossible combinations (eg, not sampling “Jersey” after “Leonardo”), the authors build a prefix tree (trie) which encodes 6M Wikipedia titles in a decent 600 MB index. GENRE is also parameter-efficient 🏋 : while DPR or BLINK require 30–70GB of memory and 6–15B (billion) parameters, GENRE only requires 2GB and 17M (million) parameters!
 Generating entity names token by token. Source: GENRE github repo
Generating entity names token by token. Source: GENRE github repo
By the way, a multilingual version, mGENRE, has been published and released either 😉
Complex Question Answering: More Modalities
Research on open-domain QA often employs graph structures between documents as reasoning paths (whereas KG-based QA directly traverses a background KG). Open-domain QA immediately benefits from enormously large LMs and recent dense retrieval techniques, that’s why more efforts from big labs are put along this dimension.
First, Xiong, Li, et al extend the idea of Dense Passage Retriever to the multi-hop setup where complex questions are answered iteratively step by step. During training, you’d feed MDR (Multi-hop Dense Retriever) with a question and previously extracted passages together with positive and negative samples of possible passages, so it’s pretty close to the original DPR. At inference (check the illustration below), the authors apply beam search and MIPS to generate top-K passages, score them, and prepend best candidates to the query at the next iteration. Pretty much all existing multi-hop QA datasets can be solved in 2–3 steps, so it’s not a big burden on the system.
🧪 Experiments show that the graph structure is not necessary here. That is, you could omit mining and traversing links between paragraphs and resort to the dense index alone to get even better prediction quality! On average, MDR is 5–20 absolute points better and 10x faster than its contenders. Besides, does the chosen approach (beam search over pre-trained index) resemble conceptually CQD for KG query answering from the first section? 😉
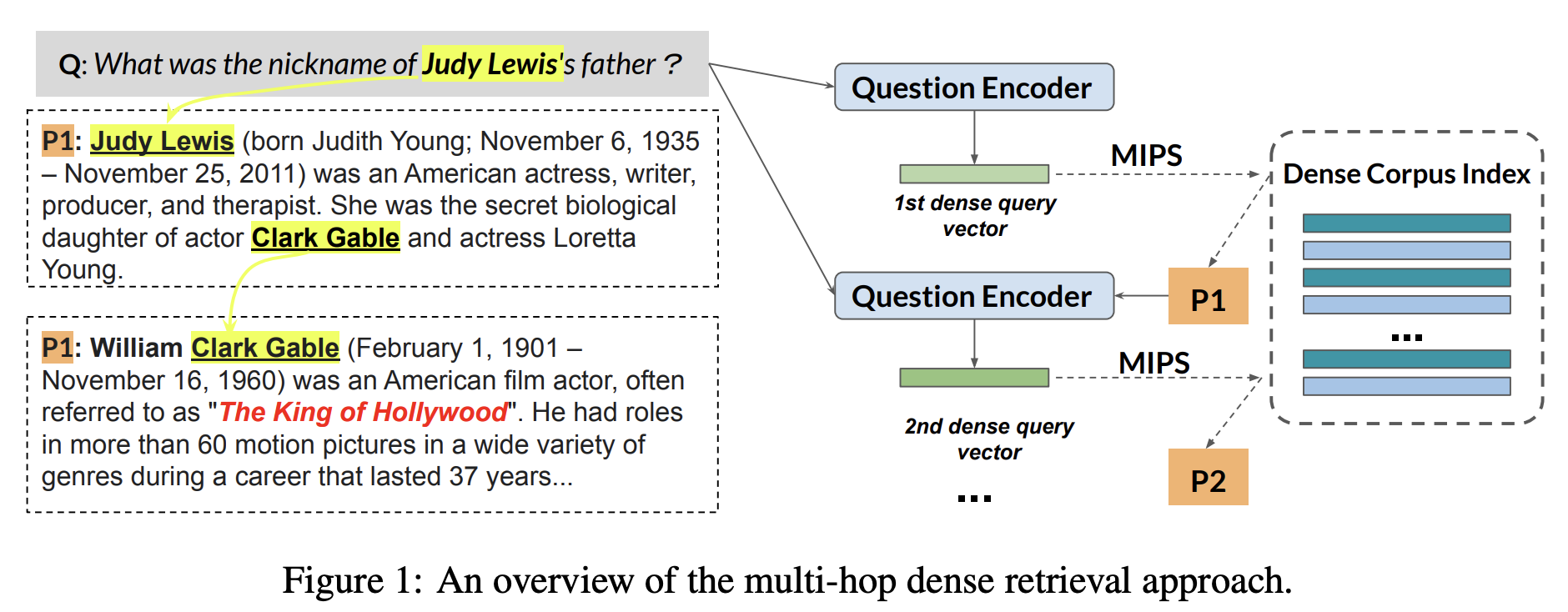 MDR intuition. Source: Xiong, Li, et al
MDR intuition. Source: Xiong, Li, et al
While MDR focuses on passages of pure text (being them extracted from Wikipedia or other text-only sources), a continuing trend is to cover more sources beyond flat texts. To this end, Chen et al study the problem of complex QA over both tabular and textual data and construct a new OTT-QA dataset (Open Table-and-Text Question Answering). The authors suggest an elegant solution of linearizing tables into table segments to be put into the transformer: split a table in rows and prepend to each row some common information about the whole table (eg, title, min/max values). Doing so, 400k original tables were transformed into 5M segments which is a difficult enough task for the table retriever. Conversely, the proposed model has to learn to retrieve both relevant segments and text passages.
In the experiments, the authors find that a traditional BERT-based iterative retriever-reader works quite poorly (10% F1 score) and instead propose to group connected passages and table segments together into fused blocks. Such an early fusion is achieved through entity linking of cells contents to textual mentions. Stacking all the goodies (fusion + long-range transformers + improved reader) the quality increases to 32% F1 💪. In the last sentence of the paper the authors ask: can we employ even more modalities into the QA..?
 Source: Chen et al
Source: Chen et al
… And Talmor, Yoran, Catav, Lahav et al answer this question right away in their work building MultiModalQA! A new dataset poses a multi-hop cross-modal reasoning objective over text 📚, tables 📊, and images 🖼. Cross-modal here means that at least one hop in a question implies querying another modality. In the example, a question consists of 3 hops, and each hop can be answered by a relevant source in its own modality. Overall, the dataset consists of ~30K QA-pairs spanning across 16 different compositional templates (eg, combining answers from one table and one image, a template will indicate which modalities have to be queried).
👩🔬 Empirically, the authors show that one-modality baselines yield only about 18 F1 points, while a fused model (called ImplicitDecomp) which derives modalities from classified templates returns ~56 F1 📈. Text and table QA modules use RoBERTa-Large while the visual QA module employs VILBERT-MT. It’s still far from a human score of 91 F1, so take a note — there is a new unsaturated benchmark 😉.
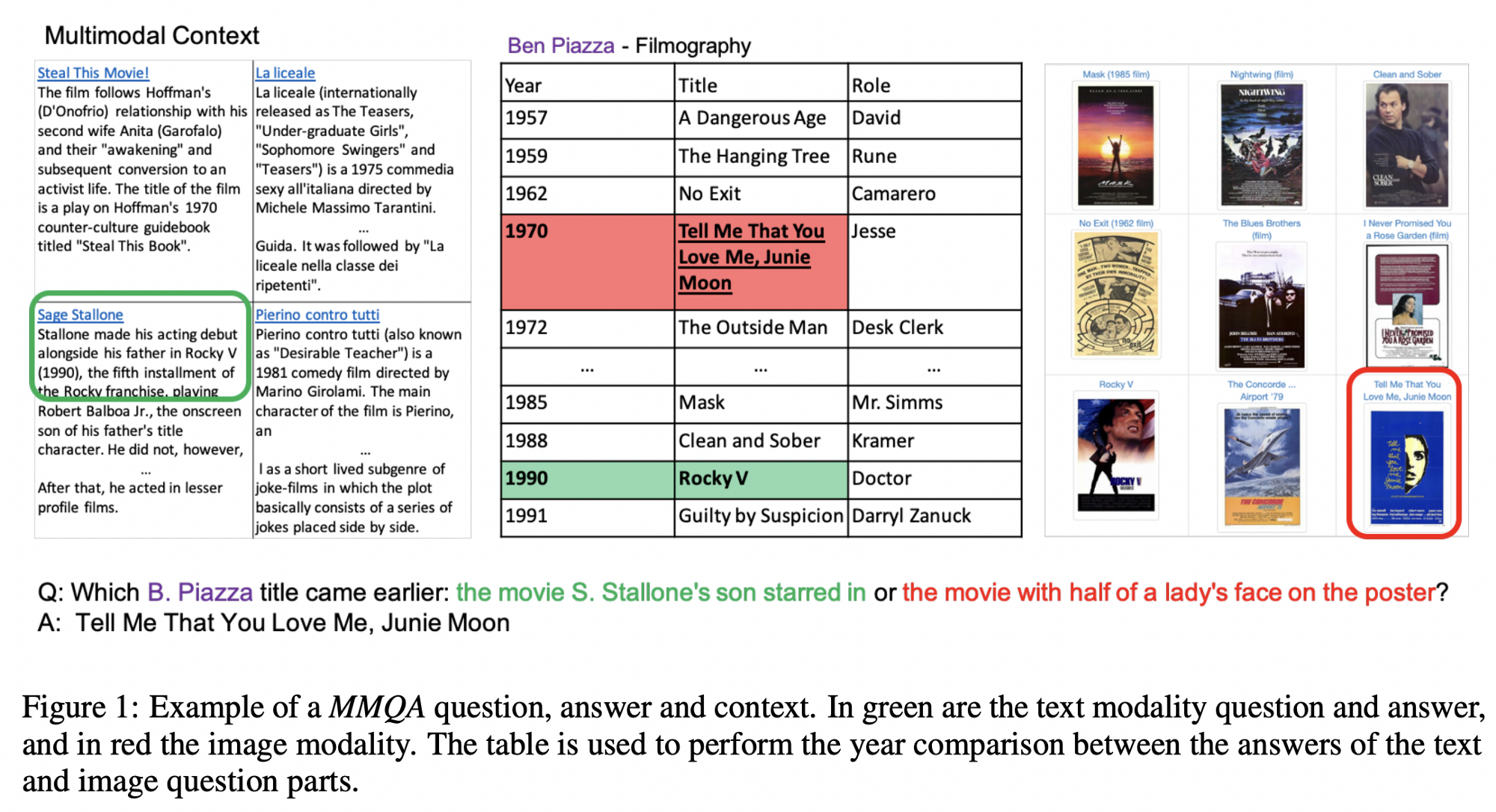 Source: Talmor, Yoran, Catav, Lahav et al
Source: Talmor, Yoran, Catav, Lahav et al
Conclusion
That’s all for today! This conference year, we have seen a lot of examples of out-of-the-box thinking (eg, in KG reasoning, entity linking, drawing parallels to similar domains) which lead to actually cool results - and I would encourage you to try out the same! Maybe that unusual idea you’ve been dismissing recently is actually worth trying?