PPLM Revisited: Steering and Beaming a Lumbering Mammoth to Control Text Generation
25 Mar 2022 | natural-language-generation reproducibility generalizationIn this blogpost, we examine to which extent PPLM can control Language Models by investigating reproducibility, the impact of the prompt vs. BoW, effect of using weighted BoW and style control. Want a summary only? Check our TL;DR.
- Introduction
- Reproducibility
- Investigating the interplay between prompt and wordlist
3.1. Using PPLM to generate questions and text for more specific topics
3.2. Weighted BoW: Addressing the focus of the PPLM to common English words in the BoW
3.3 Concluding with the mammoth metaphor - Controlling text complexity with PPLM
1. Introduction
With access to extensively pre-trained language models such as GPT-2/3 [Brown et al., 2020], [Radford et al., 2019], there is tremendous progress in the field of Natural Language Generation (NLG). Although these models can produce readable and coherent text, letting users influence the generated text by steering towards desired topics or attributes is a challenging task. The Plug and Play Language Model (PPLM), introduced at ICLR 2020 [Dathathri et al., 2020], was one of the first works on controlled text generation. The Plug and Play (PP) component optimizes the output of a pre-trained language model towards containing certain topics or text attributes. PPLM employs a pre-trained language model (LM) that generates text based on a given prompt. The LM itself is not adapted, rather controllability of text is achieved by adapting the likelihood of words to be generated by either a Bag-of-Words (BoW) related to a desired topic, or a discriminative classifier to control, e.g., the sentiment of a sentence. Due to its simplicity and ease of use, PPLM has been widely adopted. At the time of this writing, the ICLR 2020 publication has been cited more than 200 times and the official implementation received >800 stars on GitHub. It also served as a basis for new controllable NLG models in various domains, such as controlled counterfactual generation of text [Madaan et al., 2021], belief-based generation of argumentative claims [Alshomary et al., 2021] and fact-enhanced synthetic news generation [Shu et al., 2021]. In this blogpost, we examine to which extent language generation can be controlled by investigating reproducibility, the impact of the prompt vs. BoW and style control.
PPLM and mammoths
In a blogpost accompanying the original paper, the authors compared language generation models with “unguided wooly mammoths that lumber wherever they please.” A language model (LM) generates a text word by word, similar to a mammoth lumbering step by step. Using this metaphor, PPLM was presented as a mouse sitting on top of the mammoth and telling it where to go. We can clarify PPLM further by including trees in the metaphor representing words. The path of a mammoth is then represented by the trees the mammoth passes on its way and consequently represents the sequence of words that is generated. By steering the mammoth towards specific trees, the mouse has control over the generated text (see Figure 1.1).

Figure 1.1: The sequence of words is represented by a mammoth passing trees. Each tree represents a word.
Contributions
Although this mammoth-mouse metaphor is an excellent representation of the general idea behind PPLM, it does not cover the full behavior of PPLM. With a set of experiments, we analyze PPLM in more depth and subsequently extend the mammoth metaphor to explain the workings of text controllability. Specifically, we analyze how well and to which extent the mammoth follows the mouse’s instructions. We first evaluate the reproducibility of PPLM in order to provide a baseline regarding the validation of PPLM. Second, we analyze the interplay between the prompt and the BoW and their impact on the controllability of text by experiments on generating topic-related questions. We interpret the results by extending the mammoth metaphor: in section 3.3 we introduce beams and islands (we keep it an intuitive metaphor, promise!). We investigate the BoW further by analyzing the importance of words within a bag, and propose an adaptation with a weighted BoW to account for general frequency of words in the English language. We summarize our conclusions from these experiments in a more comprehensive metaphor. In this way, our metaphor provides more insights into the workings of PPLM and, to some extent, into NLG controllability in general. Third, we experiment with controlling language complexity of generated text while maintaining the topical content.
The code for reproducing our experiments can be found here: https://github.com/mcmi-group/ICLR22-PPLM-Revisited.
2. Reproducibility
Verifying the results and findings of scientific publications can motivate the scientific community to adapt those findings faster and improve upon them. In addition to the evergrowing complexity involved in training and evaluating models, this has led the Machine Learning community to put higher value on reproducing scientific outcomes, and encouraged authors to publicly share the code and data used in their published research.
Experimental setup In this experiment, we aim to reproduce some of the results that are presented in [Dathathri et al., 2020] using the Colab notebook and the Github repository provided by the authors. More specifically, we prompt the language model with the prefix “The potato” (same as in the paper) and try to steer it towards a certain topic using a BoW. We use the “military” BoW provided by the authors, i.e., a set of words related to military, such as “war”, “bomb”, “attack”, etc.
Results We compare the results found by the original authors by executing the provided Colab notebook locally, first by leaving hyperparameters unchanged and then finetuning hyperparameters, following the author’s recipe. This finetuning comprises an increase of the learning rate (step size $\alpha$) in order to generate more topic-related words and a raise of the KL divergence $\lambda_{kl}$ to produce more fluent examples. Results are shown in the below, with words from the BoW highlighted in red (click the example to expand full details).
Although two of the three texts generated by the authors contain words from the military BoW, those texts do not make much sense. Probably because it is difficult for the language model to combine the potato prompt with a military context. When we run the provided code locally (without hyperparameter change), we get even poorer results: only one of the three generated texts contains a military word, and the context seems more related to cooking than military. After tuning the hyperparameters according to the authors’ recipe, topic relatedness increases, i.e., all texts contain words from the military BoW, but without a real connection to “potato.”
Table 2.1: Results from Colab Notebook for prompt "The potato", BoW "military". Red indicates words in the BoW (click to show full table)

We repeat the experiment with the authors’ code provided on Github with similar results: finetuning the hyperparameters leads to more military flavored texts, but the example from the paper is loaded with a lot more military words.
Table 2.2: Results from Github repository for prompt "The potato", BoW "military". Red indicates words in the BoW (click to show full table)

Hyperparameter analysis
Beyond the reproduction, we explore the effect of hyperparameter configurations on the quality of generated text in terms of perplexity (PPL) under a language model [Radford et al., 2018] as a proxy for fluency and the number of distinct n-grams (Dist) as a measure of repetitiveness [Li et al., 2016].
Experimental setup We focus on 4 hyperparameters - step size $\alpha$, KL-scale $\lambda_{kl}$, grad-length and GM-scale $\gamma_{gm}$ and study how the quality of the generated text (in terms of perplexity and distinctiveness) changes with various hyperparameter configurations. Our methodology is as follows:
- We randomly select 400 different hyperparameter configurations, generated from the combination of the following values (numbers in square brackets indicate [start:end;interval]): step size $\alpha$
[0:0.1;0.01], KL-scale $\lambda_{kl}$[0:0.1;0.01], grad-length[0:20;2], GM-scale $\gamma_{gm}$[0:1;0.1]. For each configuration, we perform steps 2 to 4. - For PPLM text generation, we use the prompts and BoWs from the subsequent Section 3 and Section 4, resulting in a total of 31 prompts and BoW combinations.
- For each prompt+BoW combination, we generate 5 texts of length 20.
- We calculate and average perplexity and distinctiveness over all generated samples for all the prompt+BoW combination.
Results From the two parallel coordinate plots below in Figure 2.1 and Figure 2.2., we observe the following:
- For lower perplexity (more fluent text), higher values of all hyperparameters are better.
- For higher distinctiveness (more unique n-grams), lower GM-scale is better. This result is in line with the comments on the original PPLM GitHub page, where the authors suggest to decrease the GM-scale to address repetitiveness in the generated text.
- From Figure 2.2. we cannot derive much information about the other hyperparameters, due to over-cluttering. However, after re-arranging the verticals, moving step size closer to distinctiveness, we observed the same pattern: lower step size yields higher distinctiveness. These extra plots generated after re-arranging the verticals can be found in this notebook.
- Thus, perplexity and distinctiveness are contradicting targets in terms of hyperparameter configuration.
 |
 |
| Figure 2.1: parallel coordinate plot for perplexity. | Figure 2.2: parallel coordinate plot for distinctiveness. |
We conclude from the reproduction and hyperparameter analysis, that steering language generation towards a certain topic is feasible, but requires careful hyperparameter tuning. We cannot simply optimize hyperparameters for topical coherence, but need to account for perplexity and distinctiveness as well, which are already challenging to tune on their own. Even with a suitable hyperparameter configuration, that balances between fluency and repetitiveness, topical coherence between the original prompt and the desired topic is not guaranteed.
3. Investigating the interplay between prompt and wordlist
3.1 Using PPLM to generate questions and text for more specific topics
The original publication [Dathathri et al., 2020] evaluated PPLM on general domains, both in the prompt (e.g., “potato”) and the topics steered to, like military, science and politics. We want to explore the following - Is the mouse strong enough to steer the mammoth towards highly specific domain-related topics? What would work better for this kind of controllability: prompt or BoW? Therefore, in this subsection, we study the interplay between the prompt and BoW setting in the PPLM model and its effect on the quality of the generated text on a domain-related topic. We perform the following text generation experiments using PPLM:
- general questions
- machine-learning specific text
- machine-learning specific questions
a. Generating general questions
As questions typically start with interrogative words ['What','When','Why',...], we use the PPLM BoW mechanism and create a BoW, called ‘questions’ (q) using a list of English interrogative words and a question mark (?).
Experimental setup As questions are generally short sentences, the text length hyperparameter of PPLM was set to 10 for both experiments to prompt generation of shorter sentences. This means PPLM will generate questions with exactly 10 tokens. We evaluate two different parameter settings for question generation:
- [Q-BoW(q)] We don’t use any prompt for the text generation and set the BoW to our ‘questions’ word bank.
- [Q-prompt-BoW(?)] We set the prompt as ‘What’ for text generation and BoW as a single token ’?’.
We perform a qualitative evaluation by showing both good and (arguably) bad examples (if they could be generated) for each experiment. More examples can be found in the notebook.
Results We show the generated text in Table 3.1a with good and bad examples from each experiment.
- Our results show that [Q-prompt-BoW(?)] can generate better questions compared to [Q-BoW(q)].
- None of the sentences generated by [Q-BoW(q)] were questions. So, we could only show bad examples for this experiment.
- [Q-prompt-BoW(?)] generates good questions. However, they don’t always end with a question mark.
- This points to the fact that PPLM is better at generating questions when prompted with interrogative words like ‘What’ compared to passing the interrogative words as BoW list.
Table 3.1a: results on generating general questions. Red indicates words/tokens in the BoW (click to show full table)

b. Generating text about machine learning
In this step, we aim to generate text from a specific domain, namely machine learning. For this purpose, we use the PPLM-BoW mechanism, with BoW as ‘machine-learning’ (ml) created by picking 50 random words from a machine learning glossary, containing words like features, dataset, etc.
Experimental setup Domain-specific text is usually longer, hence, we set the text length to 50 in this experiment. We evaluate two different parameter settings for domain-specific text generation:
- [ML-BoW(ml)] We don’t use any prompt for text generation and only use BoW as our ‘machine-learning’ word list.
- [ML-MLprompt] We set the prompt to a machine learning text (MLprompt): ‘The model is trained on the Iris dataset.’ and don’t pass any BoW list.
We perform a qualitative evaluation by showing both good and bad examples (if they could be generated) for each experiment. More examples can be found in the notebook.
Results We show the generated text in Table 3.1b with good and bad examples from each experiment.
- The results show that [ML-BoW(ml)] does not generate machine learning related text. However, it is interesting to observe that the text is related to some technical content.
- The text generated from [ML-MLprompt] is quite related to machine learning.
- This points to the similar observation of experiment 3.1.a, that prompts are better at generating topic specific sentences than the BoW list.
Table 3.1b: Generating text about machine learning results. Red indicates words in the BoW (click to show full table)

c. Generating questions about machine learning
As a final step, we want to generate machine learning questions by combining both, interrogative and machine learning words.
For this purpose, we use the PPLM-BoW mechanism with our ‘machine-learning’ (ml) word list and vary the prompt.
Experimental setup As we expect domain-specific questions to be longer than general questions, but shorter than domain-specific text, we set the text length to 20. We evaluate two different parameter settings for domain-specific question generation:
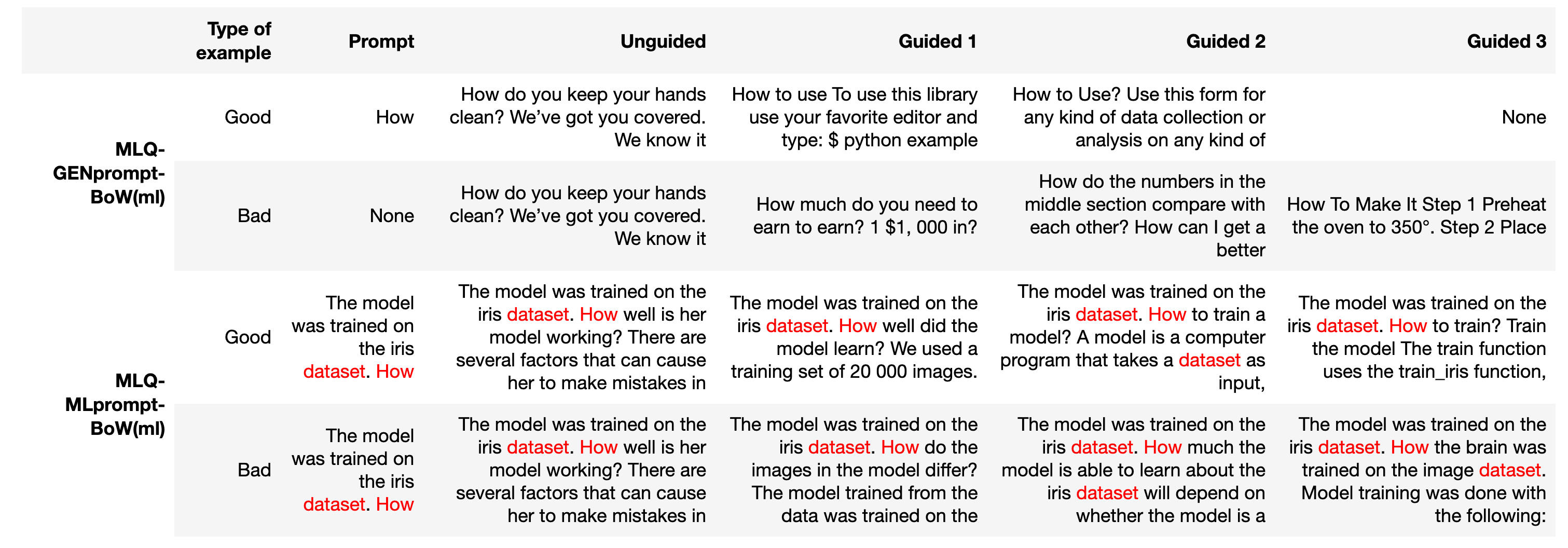
- [MLQ-GENprompt-BoW(ml)] We set the prompt to an interrogative word (GENprompt), ‘How’ and the BoW to the ‘machine-learning’ word list.
- [MLQ-MLprompt-BoW(ml)] We set the prompt to a machine learning text, ending with an interrogative word (MLprompt), ‘The model was trained on Iris dataset. How’ and the BoW to the ‘machine-learning’ word list.
We perform a qualitative evaluation by showing three good examples and three bad examples for each experiment. More examples can be found in the notebook.
Results We show the generated text in Table 3.1c with good and bad examples from each experiment.
- The results show that [MLQ-GENprompt-BoW(ml)] is good at generating general questions, but not at generating machine learning specific questions.
- The [MLQ-MLprompt-BoW(ml)] is quite good at generating machine learning specific questions.
- Thus, the observation here is in line with experiments 3.1.a and 3.1.b. The machine learning related prompt containing an interrogative word is better at generating machine learning questions than the BoW ‘machine-learning’ list.
Table 3.1c: Generating questions about machine learning results. Red indicates words in the BoW (click to show full table)
3.2. Weighted BoW: Addressing the focus of the PPLM to common English words in the BoW
In experiment 3.1.b, the PPLM model tended to steer towards the words “feature” and “dataset”,
which are the most common words among 50 machine learning words (according to Corpus of Contemporary American English (COCA)).
A potential reason could be that PPLM is updated based on
$\log p(a|x) = \log (\sum_{i=0}^k p_{t+1}[w_i])$ (Equation 4 in the original paper), which is dependent on the likelihood of each word.
In the previous experiment, the word “feature” has the highest likelihood, so most texts are generated towards this word.
To verify this hypothesis, we set up another experiment with an empty prompt and the BoW as [sport, classify, representation, instance].
We expect the word “sport” to be far more likely than the others, because it is a commonly used, general term.
Meanwhile, the other words are from the specific domain of machine learning and hence far less likely overall.
Table 3.2: Weight modification results. Red indicates words in the BoW (click to show full table)

As expected, the results show that most of the generated text is related to “sport”. Obviously, if a word in the BoW is much more common than the others, the model may ignore the less common words and might be steered towards a wrong topic. To cope with this problem, we modify the weight of each word probability. Specifically, we add a weight parameter called $v_i$ to the above equation and get:
\[\begin{equation} \log p(a|x) = \log (\sum_{i=0}^k v_ip_{t+1}[w_i]). \end{equation}\]Up-weighting less common words with this modification, we run the experiment again, and have some good and bad results in Table 3.2.
The results show that we could steer the PPLM model to less common words by increasing the likelihood of each word by additional weighting. The samples in Table 3.2 after up-weighting are closer to the technical domain than sports, which indicates the efficiency of controlling the likelihood weights.
This is just a naive approach but shows the potential of likelihood regularization. Another possible option would be to make the distribution over words in the BoW uniform. Even though we can control the distribution of words in the BOW, the generation of the desired topic strongly depends on the choice of words in the BoW. In the scope of this blog post, we only want to raise awareness for this detail and suggest some methods to go further.
In conclusion, carefully picking the words in the BoW is important to control the PPLM, and modifying the weight can help to control the PPLM to generate texts related to the desired topic.
3.3 Concluding with the mammoth metaphor
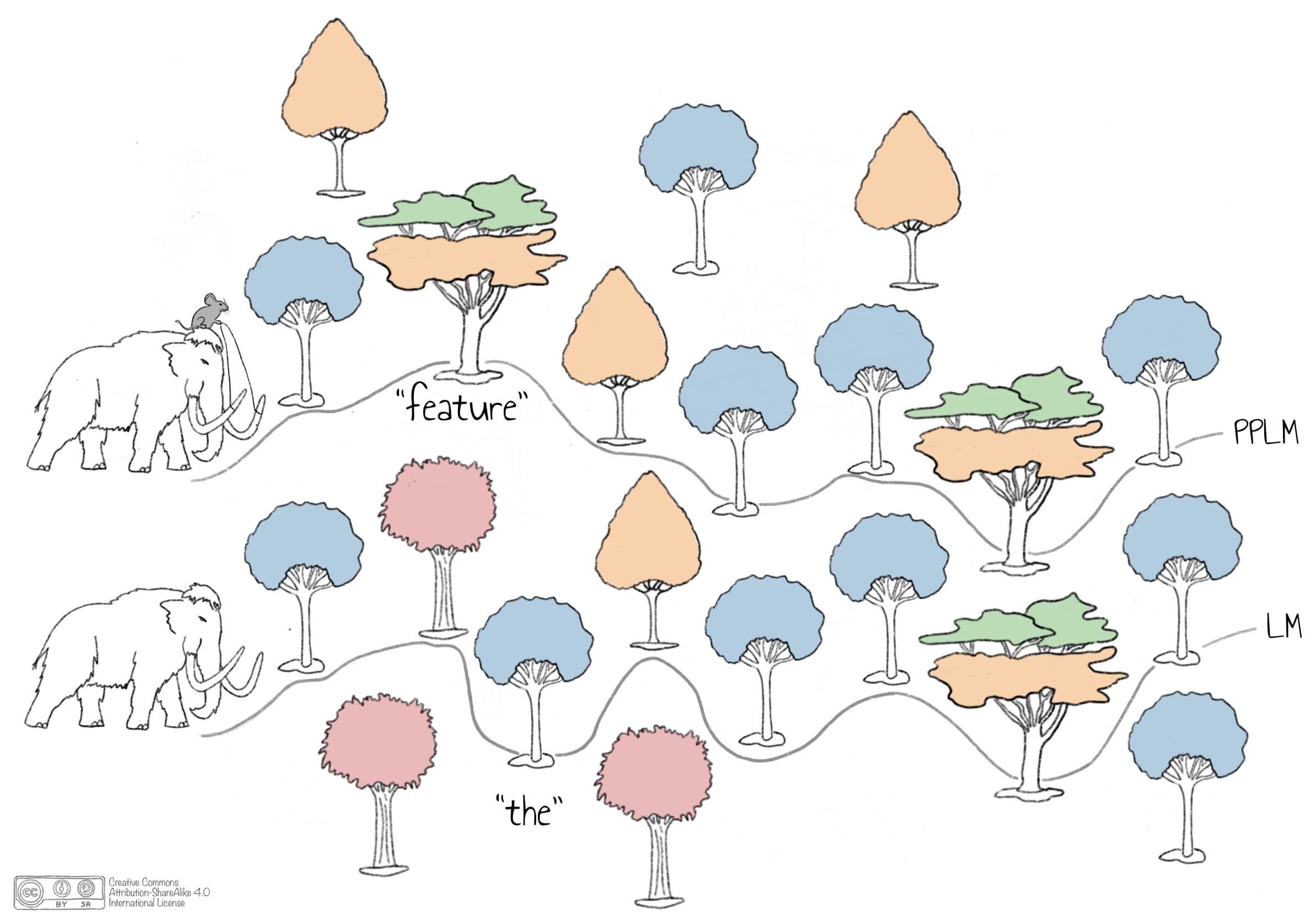
The PPLM authors compared the working of PPLM with a mouse steering a mammoth along a certain path. However, our experiments show that controlling the language model for a very specific topic (e.g., machine learning) is challenging for PPLM when only using a BoW. Using a prompt, which is part of the LM rather than PP, is more effective. Hence, we introduce the analogy of the prompt with aliens in UFO’s beaming the mammoth to a particular position in the World of Language. Without a prompt, the mammoth would start at a random position in this world, depending on the unknown, internal state of the LM. The Continent of General Knowledge, as visualized in Figure 3.1, is the largest in the World of Language making it likely that the mammoth ends up there. From its starting position, the mammoth will lumber along a path of trees, as shown in Figure 3.2 (bottom path). A standard LM might take the shortest path through the forest, passing trees representing general or specific terms in quite random sequence with the goal to generate coherent text. PPLM with a BoW acts as the mouse steering the mammoth to preferred trees (yellow, top path in Figure 3.2). The challenge is that there exist words which are topic-related but are also used in different context, such as the word “feature” in experiment 3.1.b. In such cases, BoW might be insufficient to generate good text and we need a specific prompt to change the starting position of the mammoth from the Continent of General Knowledge to a specific topic-related island. In case of a specific prompt, such as “The model was trained on the Iris dataset,” the mammoth is beamed to the Machine Learning Island, making it easier for the mouse to steer the mammoth to topic-relevant trees since there are more topic-related trees (yellow) rather than trees that also have another general meaning for the same word (mixed color). We can therefore conclude that beaming the mammoth to the right starting position is crucial for improved controlled generation of text.
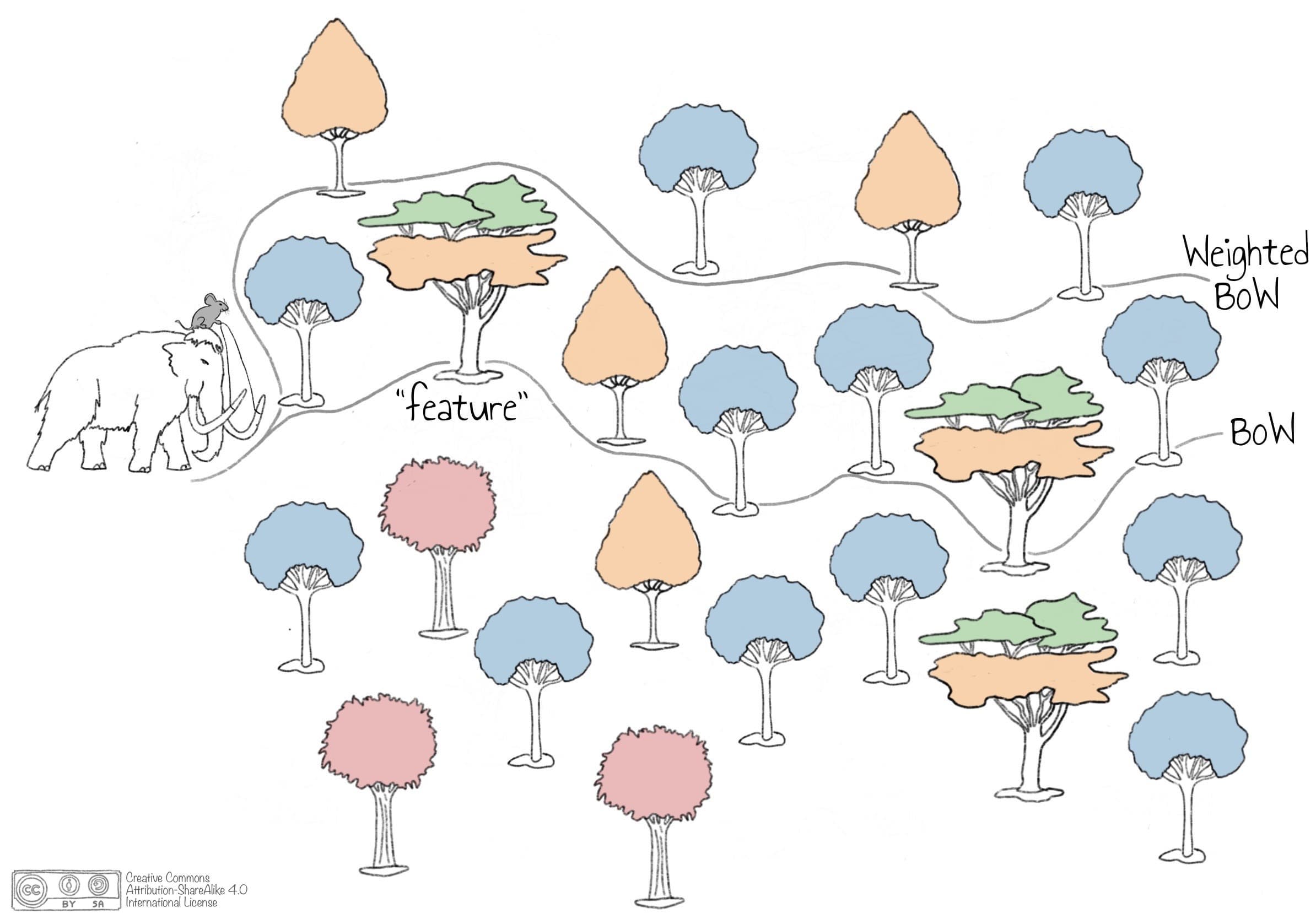
In Section 3.2, we address the issue of words having multiple meanings in more detail. We show that in case some trees occur more often than others, represented by the multi-colored trees. Those trees are quite attractive for the mouse, and it tends to focus on those since they “have some yellow in them.” The weighted BoW approach addresses the problem by making those trees less attractive, by expressing explicit preference and adjusting the weights of words in a bag. In this way, the mouse can still steer towards the “sports” tree, but is more enthusiastic about the “classify” and “instance” trees, as visualized in Figure 3.3.
In summary, the combination of beaming the mammoth to a suitable starting position (promote) and adjusting the preferences of the mouse (weighted BoW), leads to a higher topic-relevance of the generated text.
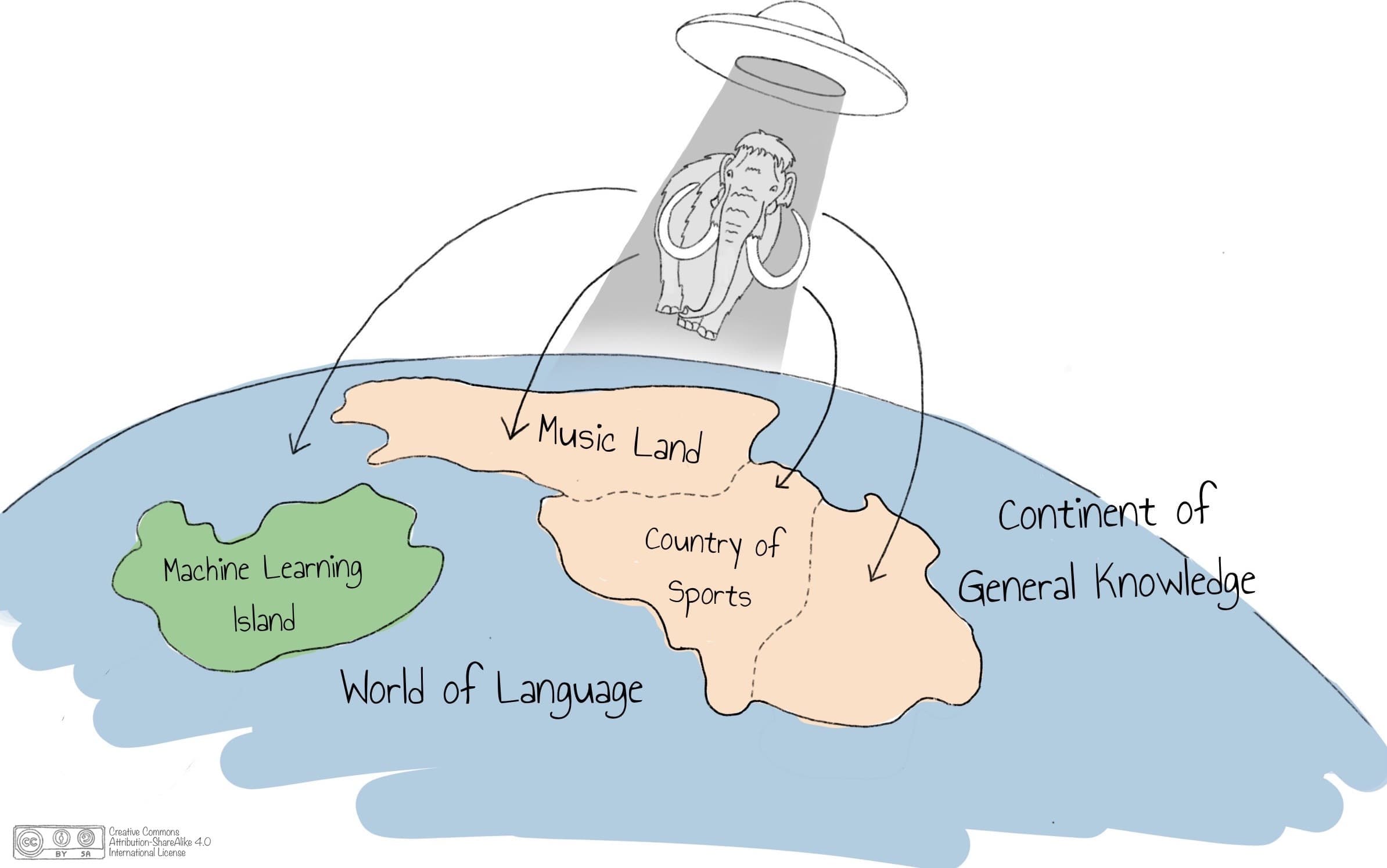
Figure 3.1: The prompt beams the mammoth to a starting position.
 |
 |
Figure 3.2: A standard language model might take the shortest path (bottom), whereas PPLM acts as a mouse steering the mammoth (top).
 |
|
Figure 3.3: Higher weights are given to topic-relevant trees that might occur less often than trees having multiple meanings.
4. Controlling text complexity with PPLM
Analogously to controlling the topic of generated text, it may also be desirable to control stylistic aspects. Intuitively, there is more than one way to express a given topic (e.g., formal, informal, polite, knowledgable, etc.) and the appropriate formulation depends on the context [Ficler and Goldberg, 2017]. This has important applications in, for example, conversational agents where a system may choose to use a different tone depending on the needs of the dialog partner [Smith et al., 2020].
In this part we explore a simple idea: can we use PPLM to control the complexity of generated language? As a proof-of-concept, we use the PPLM BoW objective with a list of the most frequent English words. Intuitively, these words are likely to be known by the vast majority of English speakers. If the PPLM objective consistently favors common English words and stays on topic, the generated texts should be more easy to read. While the original PPLM publication only explored controlling topical aspects, this experiment evaluates if the control mechanism generalizes to stylistic aspects of text and can therefore be seen as a test for the generalizability of the approach.
Experimental setup
Our experimental setup is as follows: we use the most common 1K/2K/5K English words in the Corpus of Contemporary American English (COCA) as the PPLM BoW objective and compare with an unguided generation as baseline. We generate texts both for everyday topics in the prompt (e.g., The train, The football) and complex subjects (e.g., A radiograph is, Convex optimization is) to see how the vocabulary use differs across those contexts. We define a list of 25 prompts which are given in the listing below. For each BoW and prompt, we generate 5 samples each up to 100 tokens and select the sample with lowest PPLM loss for further evaluation.
PROMPTS = [
"The steam engine is", "The ozone layer is", "A fracture is", "Vitamine D is", "Electricity is",
"Machine learning is", "Convex optimization is", "A car is", "Gravity is", "Rain is",
"A radiograph is", "A pulmonary edema is", "A rope is", "The potato", "The football",
"The chicken", "The horse", "The pizza", "The lake", "The house", "The train", "The plain",
"The tunnel", "The mountains", "The French country"
]
Listing 4.1: prompts used in the style experiments.
To objectively compare the generated texts, we employ established NLG metrics. Following [Dathathri et al., 2020], we measure perplexity (PPL) under a language model [Radford et al., 2018] as a proxy for fluency and the number of distinct n-grams (Dist) as a measure of repetitiveness [Li et al., 2016]. In addition, we consider several metrics that are relevant to the task of generating simple language. These include surface-level statistics such as the number of generated words (Words) and the percentage of generated words that are present in the simple BoW used as PPLM objective. We refer to the latter as “Simple Word Precision” (e.g., Prec. 2K EN). Finally, we calculate unsupervised readability metrics such as the Flesch Reading Ease and Gunning-Fog index as an indication of the difficulty of generated language. For a recent review of readability measures, we refer the reader to [Martinc et al., 2021].
Setting the hyperparameters for generating simple text
As discussed above, PPLM is sensitive to the choice of hyperparameters and in particular, fluency and non-repetitiveness are contradicting targets. In the absence of a good strategy to balance between these, we adjusted the step size $\alpha$, KL-scale $\lambda_{kl}$ and GM-scale $\gamma_{gm}$ based on one prompt and manually asserted that generated texts are both fluent and show good usage of the words in the BoW.
One interesting problem is the interaction between step size and the chosen BoW. As we increased the step size, more words of the BoW were chosen by PPLM (see Example 4.1). The BoW only includes lowercase word forms, this led the language generation to produce lowercase words even at the beginning of a sentence. One might try to fix this problem by adding the capitalized forms to the BoW. However, that might result in the opposite problem where capital words are generated mid-sentence.
Prompt: How does the steam engine work?
=== PPLM generated text with small stepsize (alpha = 0.08) ===
This question is often asked in a variety of ways - some folks want to know how the steam engine
works, some folks want to know how much electricity is used to create the steam, etc. The truth is,
we don't know, but we do know that it is not that simple and is a lot of work. The steam engine is
very complex machine and is very difficult to explain and explain in a simple manner. The only way
is through science - and that is not how it [...]
=== PPLM generated text with large stepsize (alpha = 0.2) ===
Generation: the steam is the main source of power for the steam engine and all other parts of the
ship. and it is a huge part of the overall weight of the ship. and the amount of power is not the
only reason for the weight and [...]
Example 4.1: interaction between step size $\alpha$ and the BoW of most common English words. As the step size gets too large, only words of the BoW are chosen which leads to sentence starts with lowercase word forms.
Quantitative evaluation of generated samples
To answer the question if the BoW mechanism is suitable to control text complexity, we are first going to look at the automated analysis of generated samples (see Table 4.1 and Figure 4.1). We make following observations:
- BoW samples have comparable fluency (
PPL) and a consistent diversity (Dist). Relative to the unguided generation, the samples generated with PPLM appear still fluent and show a high diversity. - All samples drawn with PPLM include a significantly higher portion of words from the word list. This confirms the effectiveness of PPLM as a mechanism to steer the generation of text. Across PPLM objectives (BoW of length 1K/2K/5K) we do not see a difference in how many words are included from the respective word lists.
- Samples generated with PPLM are on average longer than unguided samples in the number of words. This is because of the underlying Byte-Pair Encoding (BPE). During generation we’ve set the maximum sample length to 100 tokens. However, since a word may consist of multiple tokens in BPE, the number of words is at most the number of tokens. As we see that PPLM samples consist of more words, we can infer that more common words are sampled (i.e., words which do not have a subword segmentation).
- We do not see a significant reduction in reading complexity when considering traditional readability measures. The results across the four readability metrics are inconclusive. While we observe increased readability in the Flesch Reading Ease and Coleman-Liau index, readability according to Gunning-Fog Index and ARI decreased.
Table 4.1: quantitative evaluation of generated texts for text complexity experiment. Metrics are averaged over 25 samples for each PPLM objective.
| PPLM objective | PPL | Dist. | Words | 1K Prec. | 2K Prec. | 5K Prec. | Flesch (↑) | Gunning-Fog (↓) | ARI (↓) | Coleman-Liau (↓) |
|---|---|---|---|---|---|---|---|---|---|---|
| Unguided | 33.2 | 0.82 | 81 | 0.61 | 0.68 | 0.76 | 69 | 10.6 | 9.8 | 7.6 |
| BoW English 1K | 23.8 | 0.84 | 91.7 | 0.79 | 0.84 | 0.88 | 70.8 | 11.7 | 10.3 | 6.1 |
| BoW English 2K | 29.6 | 0.84 | 90.2 | 0.76 | 0.84 | 0.88 | 70.6 | 12 | 10.4 | 6.4 |
| BoW English 5K | 26 | 0.84 | 93.2 | 0.76 | 0.82 | 0.89 | 70.1 | 12 | 10.8 | 6.7 |

Figure 4.1: distribution of values for selected text complexity metrics of Table 4.1.
Qualitative evaluation of generated samples
To get a better understanding of how the BoW objective influences text readability, we next turn to a few examples. We present both samples with high simple word precision (see Table 4.2) and samples with low simple word precision (see Table 4.3). For prompts on complex subjects (e.g., A pulmonary edema is, Gravity is) we see that the PPLM samples contain substantially less “technical” terms compared with the unguided sample. For many of the prompts of everyday subjects (e.g., A car is, A rope is), we cannot observe the same trend.
Table 4.2: examples with a high simple-word precision: the PPLM guidance leads to qualitatively less complex texts. Red indicates words that are NOT in the bag of simple words. (click to show full table)

Table 4.3: examples with a low simple-word precision: the PPLM guidance does not substantially reduce text complexity. Red indicates words that are NOT in the bag of simple words. (click to show full table)
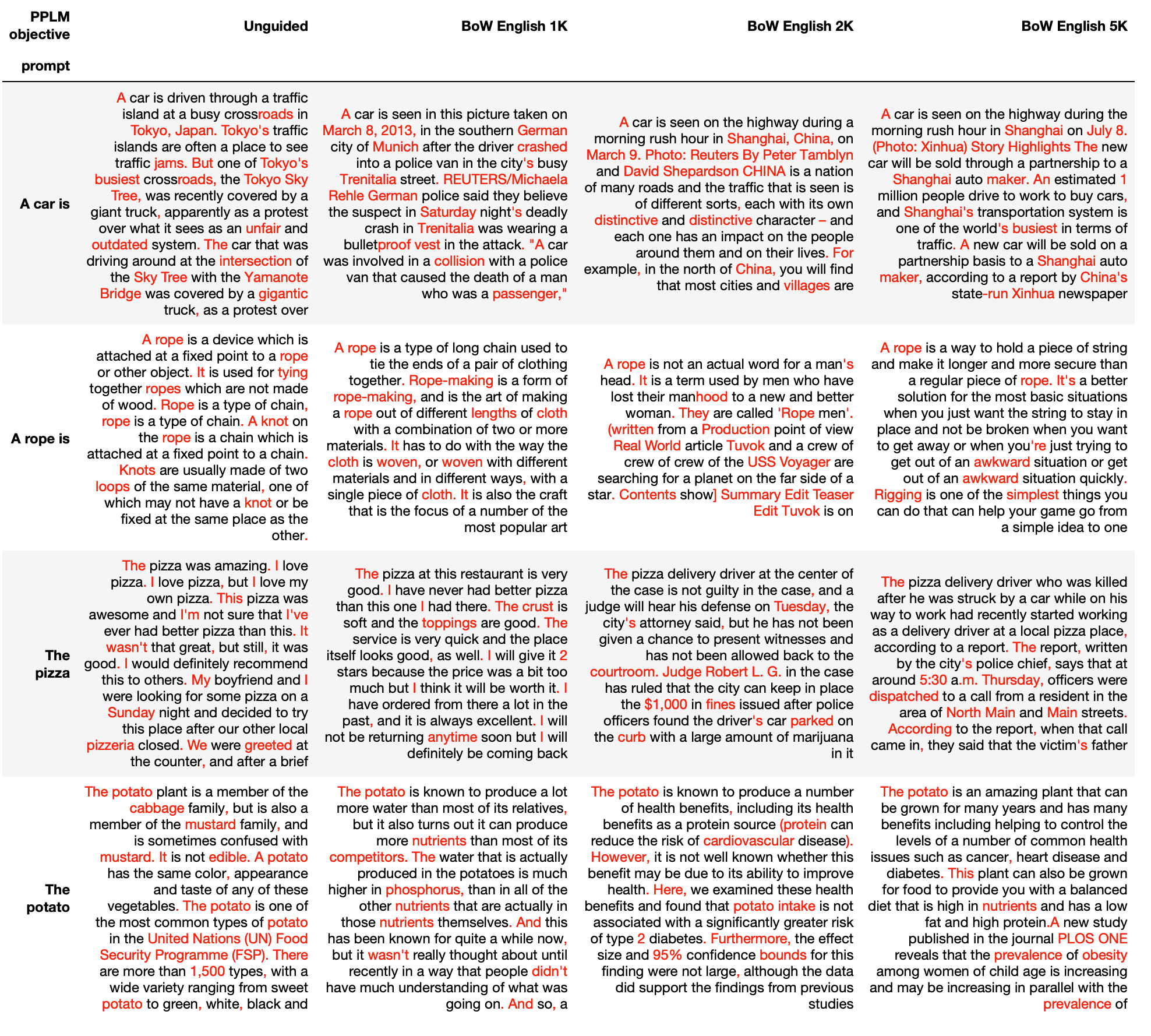
In summary, we observe the PPLM model picking up on terms from the provided BoW, but we do not observe a conclusive influence on language complexity with the BoW approach. Speaking in terms of the mammoth metaphor, the mammoth can be beamed to a particular position in the world of language via the prompt and steered towards particular trees by the mouse on top of its head (PPLM with BoW). How fast the mammoth moves from tree to tree remains uncontrolled.
TL;DR Summary
In order to control text generation of a pre-trained language model, the Plug and Play Language Model (PPLM) acts as a mouse that steers a lumbering mammoth from tree to tree in order to influence the text generation. The mouse receives a Bag of Words (BoW) that represents the relevant trees, and we suggest to use weighted BoW to give higher preference to rare, but relevant words. We also experimented with steering the mouse to simpler words in order to reduce text complexity while maintaining topic relevance. Our reproducibility experiment and hyperparameter analysis show that it is challenging to make the mammoth move in the proper way. Most influential for topic controllability is the prompt, which is part of the language model rather than PPLM. We compared the prompt with aliens in UFO’s beaming the mammoth to a particular position in the World of Language. Without a prompt, the mammoth will start at a random position and is likely to end up in the Continent of General Knowledge. When specifying a topic-related prompt, the mammoth will already start in a relevant area, such as the Machine Learning Island. Hence, beaming the mammoth makes it easier for the mouse to steer the mammoth to the right trees.
How fast the mammoth moves and whether it walks, dances or rolls from tree to tree, remains its own will.

Acknowledgement
We thank Marion Koelle (https://marionkoelle.de/) for creating the amazing drawings presented in this blog post.

All illustrations are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.